Se vogliamo che un giorno il nostro sito web possa essere utilizzato anche da utenti all'estero, è bene organizzarsi sin dall'inizio per lasciare la porta aperta, onde evitare di avere brutte sorprese. Vediamo perché: se il nostro sito offre solo pagine web, senza il supporto di una base dati, il problema può essere anche rimandato, e risolto in un secondo tempo. Se invece gli utenti possono inserire o consultare testi salvati in un database, è bene correre subito ai ripari e verificare la configurazione dell'encoding, ovvero la codifica dei caratteri.
Introduciamo brevemente il concetto per i meno esperti. La codifica dei caratteri, set di caratteri o character enconding, è la “tabella” che fa corrispondere i caratteri visualizzati sullo schermo con i numeri memorizzati nel file system. Perché abbiamo bisogno dell'encoding? Il motivo è che ogni file viene memorizzato come sequenza numerica, non come sequenza di caratteri, quindi serve una tabella di codifica per sapere cosa visualizzare quando il file (o la stringa) viene letto come sequenza di numeri.
Purtroppo non c'è un'unica tabella di questo tipo, ma esistono diverse scelte possibili, come ad esempio le codifiche UTF (UTF-8, UTF-16 ecc.), UCS (UCS2, UCS4 ecc.) ed altre ancora. Queste codifiche sono identificabili usando sigle più leggibili, ad esempio la codifica ISO-8859-1 viene detta anche Latin-1.
Siamo finalmente arrivati al nocciolo. La codifica Latin si chiama così proprio perché gestisce i caratteri dell'alfabeto latino, che sono quelli predominanti nel mondo occidentale. Ciò significa che se un domani volessimo offrire pagine web in greco o in cirillico, potremmo avere dei problemi di codifica.
Vediamo un esempio di soluzione nel caso di MySQL.
L'installazione di default di MySQL solitamente non implica la configurazione corretta, che in questo caso è la UTF-8. Per verificare se il database sta usando la codifica giusta eseguiamo la query
SHOW VARIABLES LIKE 'character\_set\_%';
che di dirà quali codifiche stiamo usando. Una configurazione errata potrebbe essere
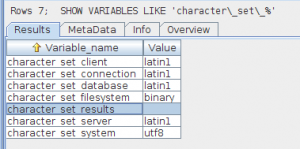
Encoding latin1
perché abbiamo ben quattro codifiche latin, là dove sarebbe meglio avere UTF-8.
Nel caso di MySQL la codifica del database è fissata quando creiamo il database, e non può essere cambiata in un secondo tempo. Per questo motivo è buona norma impostare subito il database in modo appropriato, prima di inserire i dati. Un modo di costringere MySQL ad usare sempre la codifica UTF-8 è aggiungere alcuni parametri nel file my.cnf, che dovrebbe trovarsi qui
/etc/mysql/my.cnf
i parametri da aggiungere alla fine del blocco [mysqld] sono
default-character-set=utf8
character-set-server = utf8
collation-server = utf8_general_ci
poi, alla fine del blocco [mysql], occorre aggiungere anche la riga>
default-character-set=utf8
Fatto questo possiamo riavviare mysql e creare un nuovo database. Come dicevamo prima è vano sperare di vedere queste modifiche applicate ad un database già esistente, perché la codifica va decisa alla nascita del database e non può essere cambiata. Per verificare che la nuova configurazione sia corretta eseguiamo la query (come sopra)
SHOW VARIABLES LIKE 'character\_set\_%';
il risultato corretto dovrebbe essere
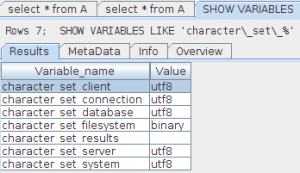
Encoding UTF8
notiamo che adesso tutte le codifiche necessarie sono UTF-8. Le altre (character set filesystem e character set result) vanno bene così come sono, per motivi che per ora tralasciamo.
Siamo finalmente pronti a popolare il database coi nostri dati, sicuri che se un giorno dovessimo inserire frasi in qualche lingua “strana” non dovrebbero sorgere problemi.
Questo riguarda solo il database, che è il primo elemento della filiera che fornisce le pagine web (vedi un esempio in questo articolo): per poter visualizzare correttamente caratteri non latini sulle pagine offerte all'utente dovremo verificare la codifica di tutti gli altri elementi, in primis l'editor che usiamo per maneggiare i sorgenti e gli script SQL. Come dice il saggio: anche un viaggio di mille miglia inizia con un solo passo.
